當全世界向云端大模型狂奔,蘋果選擇回歸設備
作者|涯角 來源|直面AI(ID:faceaibang)
幾天前,蘋果在 HuggingFace 上全面開源了視覺語言模型 FastVLM 和 MobileCLIP2,再次在 AI 社區掀起震動。
這兩款模型的直觀特征只有一個字:快。FastVLM 在部分任務上的響應速度比同類模型快出 85 倍,并且能在 iPhone 這樣的個人設備上流暢運行。但這并非一次孤立的技術秀。
與 MobileCLIP2 等開源模型一道,FastVLM 構成了蘋果“B 計劃”的核心:端側 AI 小模型戰略。
01
蘋果亮劍小模型
用最通俗的語言解釋FastVLM。它是一個“看得懂圖、讀得懂話”的多模態模型,重點有2個,1個是名字里的“Fast”——快;另一個則是“VLM”。
正如其名,FastVLM最引人注目的特點就是“快”。這種快并非簡單的性能提升,而是數量級的飛躍,使其能夠在手機、電腦等個人設備上實現以往需要云端服務器才能完成的實時任務。
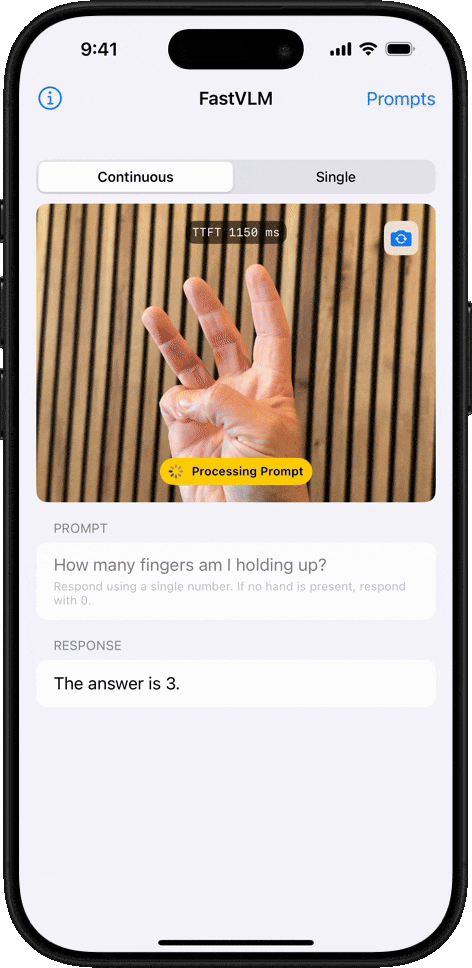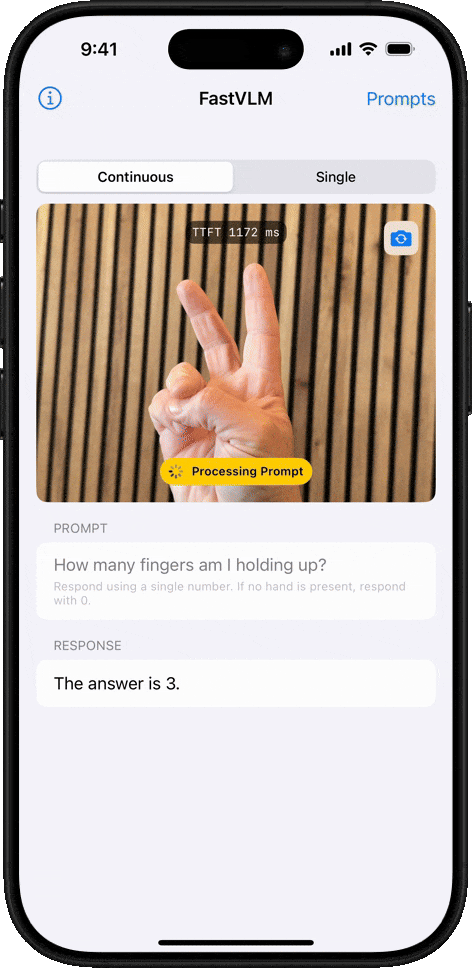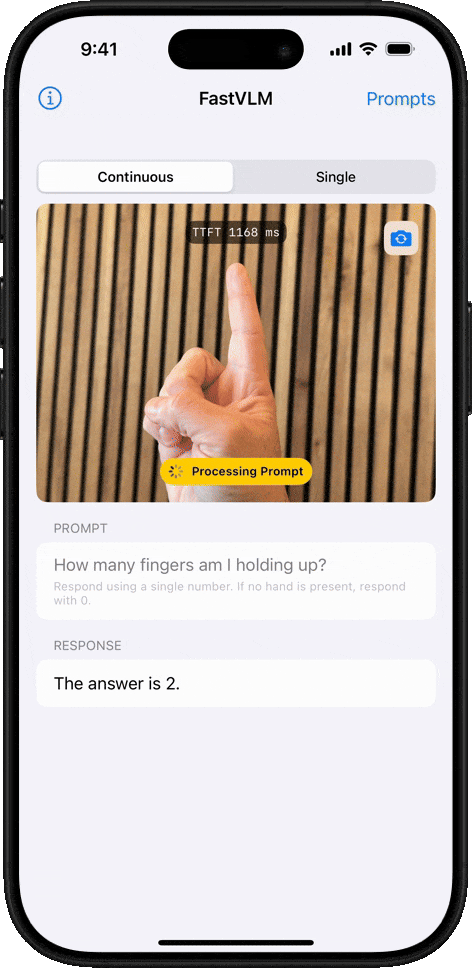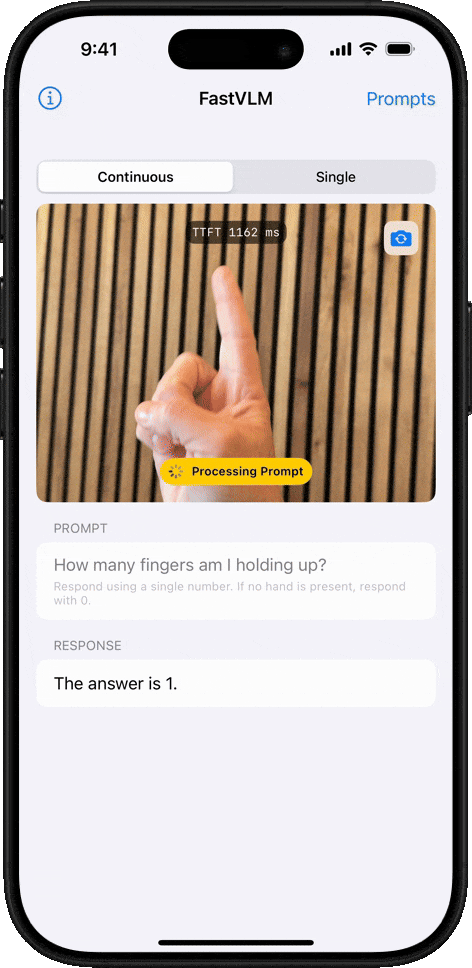
最直觀的體驗是,在生成第一個 token 的響應速度(TTFT)上,FastVLM比同類模型LLaVA-OneVision-0.5B快了驚人的85倍,而其負責“看圖”的視覺編碼器規模卻縮小了3.4倍。即使是其更強大的7B(70億參數)版本,在與近期備受關注的Cambrian-1-8B模型對比時,性能更勝一籌,同時TTFT速度快了7.9倍。
FastVLM之所以能實現速度與性能的平衡,其技術核心在于一種新型的混合視覺編碼器 FastViTHD。從技術角度看,這種編碼器能夠輸出更少的 token,并顯著縮短高分辨率圖像的編碼時間。
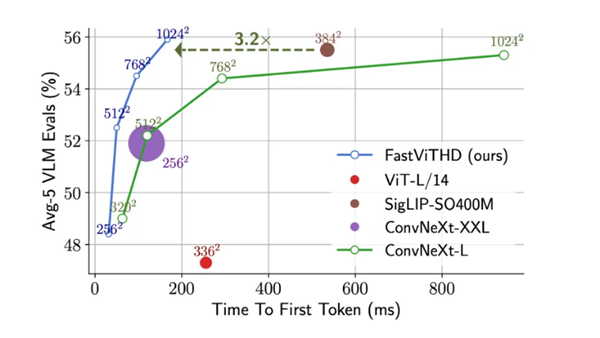
圖注:FastVLM性能表現
傳統的視覺模型在處理一張高分辨率圖片時,會將其分解成成千上萬個小塊(patches),然后將這些小塊轉化成“視覺詞匯”(tokens)交由語言模型解讀。圖片越清晰,細節越多,產生的tokens就越多,這會給后續的語言模型帶來巨大的計算壓力,導致處理速度變慢,尤其是在手機這樣的資源受限設備上。
而FastVLM的混合視覺編碼器則結合了兩種技術路徑,將卷積網絡和Transformer融合到了一起。從而,能夠在不犧牲關鍵視覺信息的前提下,輸出更少但更精華的 tokens。
因此,其作為VLM (視覺語言模型),它不僅快,理解圖像和文字的綜合能力也同樣出色,能夠在保證速度的同時,維持極高的準確性。
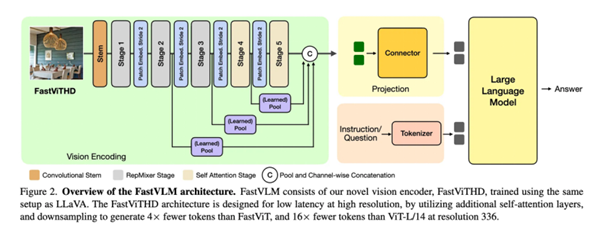
圖注:FastVLM架構
目前,FastVLM 已經上線多個尺寸,包括:0.5B、1.5B、7B版本:
憑借這樣的能力,FastVLM已經可以支持無需任何云端服務,端側的實時瀏覽器字幕等功能。
目前,HuggingFace平臺Apple開源FastVLM頁面已經提供了試用平臺。鏈接如下:https://huggingface.co/spaces/akhaliq/FastVLM-7B
我們同樣上手體驗了FastVLM的強大功能。我們選取了近期在社交媒體上廣為流傳的“馬斯克計劃將擎天柱(Optimus)機器人送上火星”的視頻作為測試材料。整個過程非常直觀,上傳視頻后,只需點擊左側的“Analyze Video”,分析就開始了:
FastVLM的處理速度確實令人印象深刻。我們粗略計時了下,單幀畫面的分析時間僅在1-2秒,甚至更短之間,系統在不到幾秒內就完成了對8個關鍵幀的提取和解讀。
以下是FastVLM捕捉到的畫面及其生成的描述:
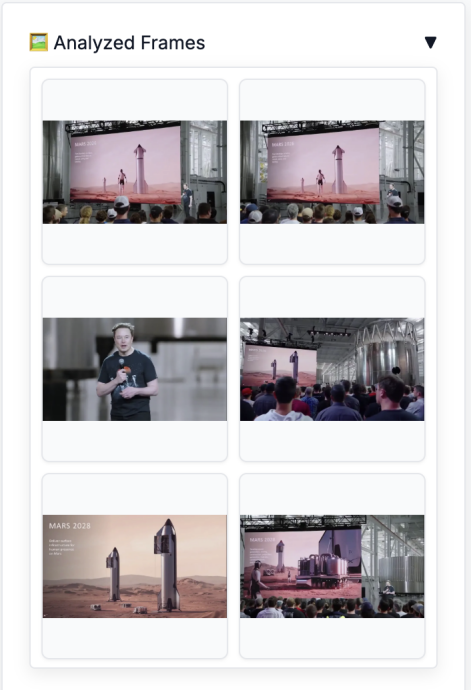
圖注:FastVLM捕捉的畫面
給出的結果則是:
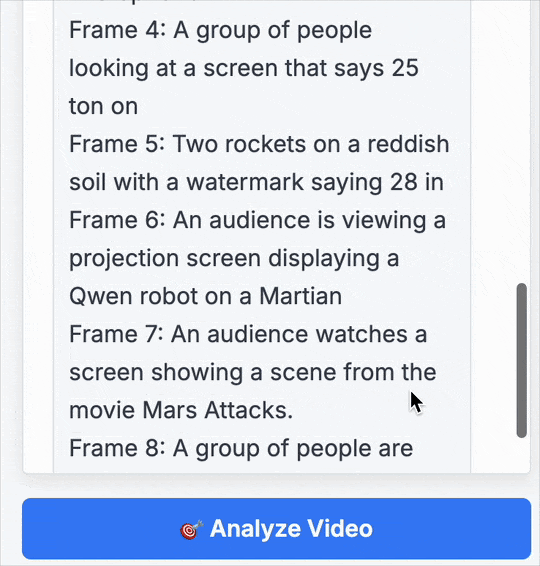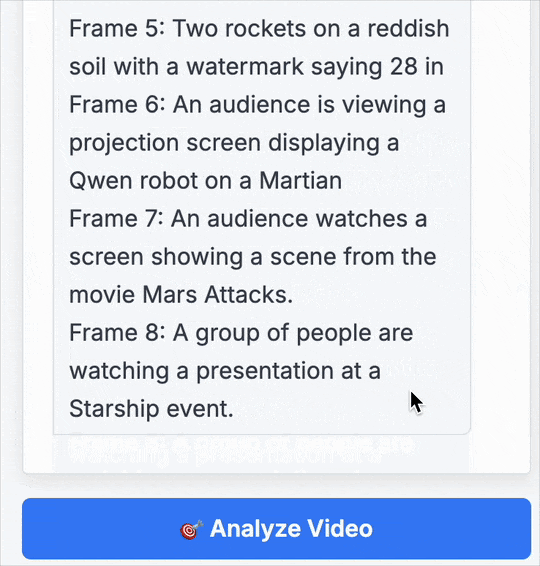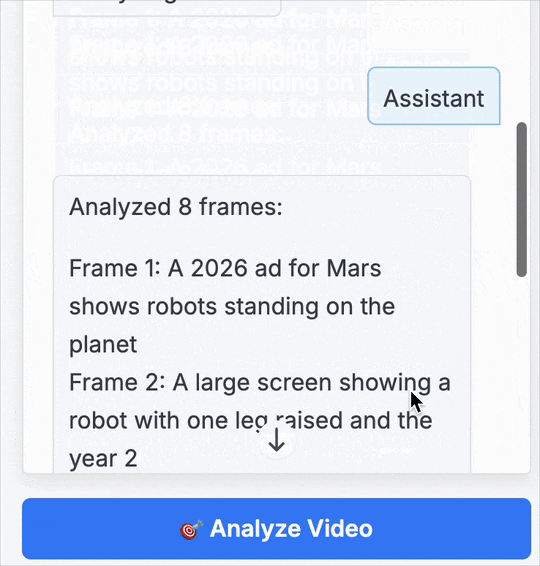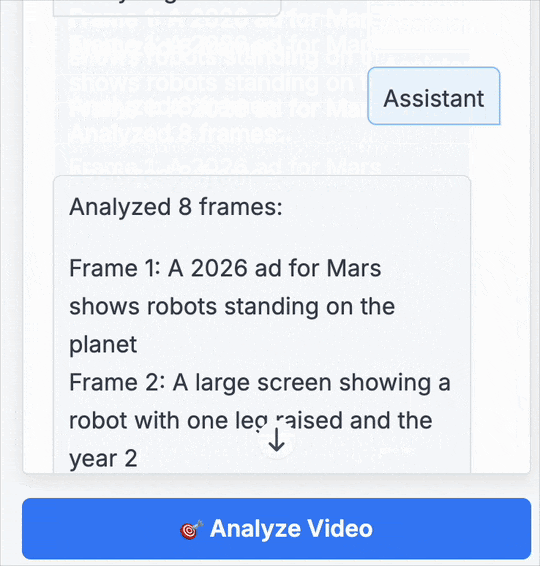
我將生成的畫面分析結果翻譯成了中文:
第1幀: 一則 2026 年的火星廣告,展示了站在火星上的機器人。
第2幀: 一個大屏幕,上面顯示著一臺抬起一條腿的機器人,以及年份“2”。
第3幀: 一位穿著黑色印花T恤的男子手持麥克風。
第4幀: 一群人正注視著屏幕,上面顯示“25 ton on”。
第5幀: 兩枚火箭立于紅色土壤之上,畫面上有“28 in”的水印。
第6幀: 觀眾正在觀看投影屏幕,上面顯示著火星上的 Qwen 機器人。
第7幀: 觀眾在觀看屏幕,播放的是電影《火星人玩轉地球》(Mars Attacks)的片段。
第8幀: 一群人正在參加星艦(Starship)活動的演示。
最關鍵的是,你會發現,FastVLM在追求極致速度的同時,并沒有犧牲準確性。經過逐一比對,我們發現生成的描述與每一幀的畫面內容都比較吻合。
除此之外,蘋果同樣準備了一個叫做FastVLM-Web GPU的項目,它可以通過攝像頭實時分析視頻流。你可以在下面這個位置找到它,點擊即可使用:
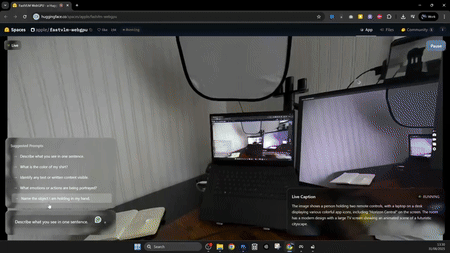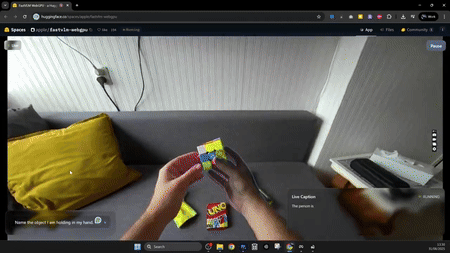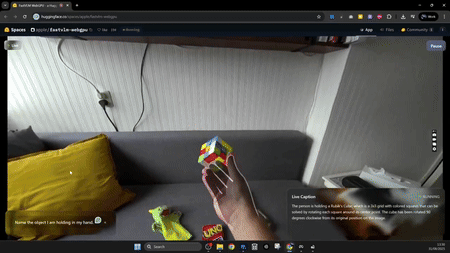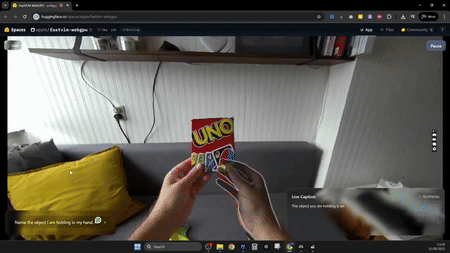
由于它的能力很強,吸引了各路網友前來試用,也有X大神@GabRoXR搞出了很有趣的測試Demo。比如,通過設置一個OBS虛擬攝像頭,將其直接接入MetaQuest頭顯中,做一個實時字幕應用:
值得注意的是,FastVLM對于本地設備的硬件能力要求非常低,比如,一個X網友@njgloyp4r僅通過Chrome瀏覽器和一塊RTX 3090顯卡,配合OBS虛擬相機及系統截圖工具,就能手搓出一個實時識別畫面的工作流:

盡管FastVLM相關文件在四個月前就已悄然現身GitHub,但此次在HuggingFace上的全面補齊,依舊引發了業界的廣泛關注和熱烈討論。
其次,FastVLM的開源并非一次孤立的技術展示,而是蘋果為其“端側AI”戰略精心打造的關鍵一環。與FastVLM一同引發關注的,還有蘋果最新開源的另一類兼顧低延遲與高準確度的圖像-文本模型 MobileCLIP2。
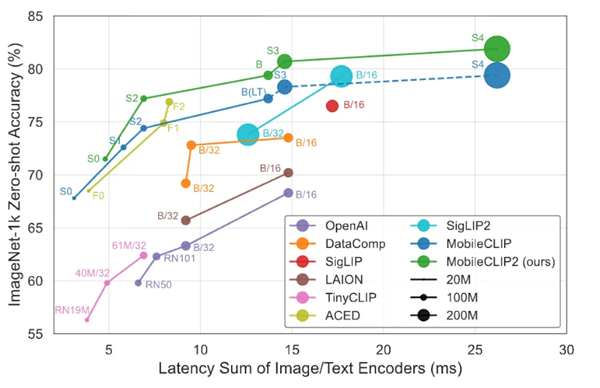
圖注:MobileCLIP2 性能表現
其同樣專注于在移動設備上實現低延遲與高準確度的平衡,它通過“多模態強化訓練”構建,目標是實現在移動設備上快速響應,但仍保持優良性能。
02
蘋果的“AB”計劃
在過去幾年洶涌的AI浪潮中,如果非要選一個“AI進展異常緩慢”的科技巨頭的話,作為全球市值最高的科技公司的蘋果必然在一眾用戶和媒體人心中默默當選。
當其他幾乎所有科技巨頭都以前所未有的速度投身于大模型的軍備競賽時,蘋果卻在其最關鍵的硬件業務與AI的融合方向上,表現出一種外界看來近乎“搖擺不定”的姿態。
從最初堅持自研的神秘與沉默,到后來突然宣布與OpenAI合作、計劃將ChatGPT集成到其生態系統中,蘋果的每一步棋都精準地踩在了媒體、投資者和用戶的“心窩”之上,表示“令人看不懂”,引發了無數的猜測與討論。
這種外界的疑慮在今年達到了頂峰。面對Google、Microsoft、Meta等競爭對手在生成式AI領域的狂飆突進,蘋果不可能在穩坐釣魚臺了。尤其是在VR/AR的戰線上,蘋果Vision Pro雖技術驚艷但市場表現平平,面對Meta Quest系列的先發優勢幾乎是慘淡收場。在至關重要的軟硬件AI結合上,相比其他幾家,蘋果更是慢到不行。
重壓之下,蘋果終于選擇正面回應。
8月1日,蘋果CEO蒂姆·庫克罕見地召開了全員大會(allhands meeting),直接回應AI挑戰,這次會議不僅是庫克對過去一到兩年間蘋果AI進展緩慢的一次正面回應,更像是一場重振軍心的“戰斗宣傳會”。庫克在會上明確表示,蘋果已經在這方面投入了“巨額資金”,并將會推出一系列“令人興奮的”AI計劃。
緊隨其后,一則重磅消息流出,印證了庫克的決心:蘋果已經內部組建了一個名為AKI的團隊,目標直指此前的合作伙伴也是業界標桿的ChatGPT。
而為此類云端通用大模型打前哨戰的,則是蘋果在過去1年里不斷在小模型方向作出的努力。如果說,以云端大模型為代表的AI是蘋果的“A計劃”,追求的是無所不能的通用智能;那么蘋果則在“偷偷地”堅定地推進自己的“B計劃”—— 小模型計劃。
在過去的1到2年內取得了大量實質性進展。然而,這些成果往往被外界有意無意地忽略了。究其原因,由于Scaling Law無數次被印證有效,AI圈子一直信奉“大力出奇跡“,所以對小模型的進展常常并不在意。
2024年7月,蘋果就曾在 Hugging Face 上發布 DCLM-7B 開源模型,這款模型的發布,在專業圈層內引起了不小的震動。其性能已經逼近、超越了當時來自基礎模型廠商的一眾同級別同尺寸模型,像是Mistral-7B、Llama 3等等這說明,蘋果在小模型的技術積累上,并說不上落后。
在WWDC 2024上,蘋果宣布Apple Intelligence 并非一個單一的、龐大的云端模型,而是由多個功能強大、各司其職的AI小模型所組成的矩陣。這些模型經過高度優化,專門用于處理用戶的日常任務,如整理郵件、潤色文稿、智能相冊搜索等。
03
當全世界向云端大模型狂奔,蘋果選擇回歸設備
蘋果想要保住基本盤,就得在端側打AI反擊戰。
蘋果的商業帝國建立在三大基石之上:極致的用戶體驗、無縫的軟硬件生態,以及對用戶隱私近乎信仰的承諾。 這三大基石,共同決定了它的AI戰略幾乎必然走向端側,走向小模型。
首先,隱私方面,蘋果在于外界云端AI基礎模型廠商的“互動”中,總是顯得有些倉促應對,媒體關于接入外部AI能力的舉措,一直質疑聲不斷。
比如,對于一個將“What happens on your iPhone, stays on your iPhone”(你的iPhone上發生的一切,只會留在你的iPhone上)作為核心營銷語的公司而言,把AI能力寄托于外部AI基礎模型廠商,被許多忠實用戶和科技評論員看來,甚至是一次“品牌背叛”。甚至有媒體稱”蘋果會保護你的隱私,而OpenAI則做不到“。

以至于蘋果后續不得不推出了AI時代的隱私保護“私有云計算”(Private Cloud Compute)等技術,也難以在短時間內完全打消市場的疑慮。
再把視線轉向國區。外界一直在猜:蘋果到底會牽手哪家本土 AI 基礎模型廠商?BAT、字節,還是新晉的 DeepSeek?
最終,有消息稱百度或成為合作對象。但很快,路透社的一則報道把爭論推向高潮——蘋果與百度在隱私問題上出現了嚴重分歧。
百度希望留存并分析來自 iPhone 用戶的 AI 查詢數據,而蘋果的嚴格隱私政策則一概禁止此類數據收集與分析。兩者在“用戶數據使用”方面產生明確分歧。

可以說,在數字時代,隱私是蘋果最鋒利的武器。而將AI計算盡可能留在設備端,是捍衛這一承諾的關鍵技術路徑之一,尤其是圖像視頻模態數據。
你想找一張“去年夏天在海邊和狗玩的照片”。在端側AI模型上,這個搜索過程完全在你手機本地的芯片上完成。你的私人照片、地理位置、甚至你和誰在一起的這些高度敏感信息,從未離開你的設備,也從未上傳到蘋果的服務器。這與需要將照片(或其特征)上傳至云端進行分析的方案,在隱私保護上有著極大的區別。對蘋果而言,選擇端側就能夠運行的小模型,首先是一道“商業倫理題”,其次才是一道“技術選擇題”。這是對其商業模式的根本性鞏固。
除了隱私保護之外,用戶體驗也是蘋果下大力氣集中攻堅小模型的動力之一。一直以來,蘋果產品的核心競爭力,在于“一旦用了,就難回到之前”的流暢體驗。端側AI是實現這種極致體驗的保障。
云端AI總會受到網絡狀況的制約,一個簡單的指令來回傳輸可能需要幾百毫秒甚至更久,這種“卡頓感”會瞬間打破沉浸式體驗。用戶的設備可能在任何地方,比如信號不佳的地下室、萬米高空的飛機上、或是異國他鄉沒有漫游信號的角落。一個依賴網絡的AI功能,在這些場景下會立刻“失靈”,而端側AI則能保證核心智能“永遠在線”。自第一代iPhone誕生以來,蘋果產品最深入人心的標簽就是“可靠感”。用戶需要一種永遠在線的“可靠感”。
其次,從性能表現來看,在公眾和部分業界的認知中,大語言模型(LLM)的參數量似乎與“智能”程度直接掛鉤,形成了一種“越大越好”的普遍印象。然而,在實際應用,尤其是在需要高度專業知識和精準度的垂直細分場景中,這種看似無所不能的“通才”大模型,其表現卻不一定比經過精細打磨的“專才”小模型更好。
最后,驅動蘋果走向端側AI的,還有一筆深藏在硬件迭代背后的、必須算清楚的“經濟賬”。近年來,一個讓用戶和評測機構都普遍感受到的現象是,iPhone的A系列和Mac的M系列芯片性能越來越強大,其每一代之間的性能突破,常常讓用戶覺得“性能過剩”了。一邊是硬件算力近乎瘋狂地增長,另一邊卻是大多數用戶在日常應用(如社交、視頻、游戲)中,無法體驗到同等速率提升的感知。
如何有效吸收并轉化這種看似溢出的邊際性能,是蘋果必須解決的核心問題。如果計算任務分配到用戶自己的設備上,利用設備上本就強大的A系列/M系列芯片,對蘋果來說,是最經濟、也最可持續的商業模式。
如果把視線從蘋果移開,會發現行業內對小模型的興趣確實在普遍升溫。但這并不意味著所有公司都在追逐同一個目標,更準確的理解是:不同公司基于其核心業務模式,對小模型有著截然不同的訴求。
像是被戲稱為AI廠商“軍火庫”的英偉達對小型語言模型的重視持續升級,在其最新研究中認為:小模型是 Agent 的未來。而眾多AI初創公司同樣開始選擇小模型,作為一種務實的某一小塊垂直市場的切入策略,像是美國醫療版ChatGPT —— OpenEvidence 等等。在通用能力上,它們難以與大廠的旗艦模型相抗衡。因此,它們選擇專注于特定行業,如醫療、金融、法律等,利用小模型易于在專業數據集上進行微調的優勢。
結尾:
放眼整個行業,雖然對小模型的興趣正在升溫,但沒有哪家公司像蘋果一樣,將其提升到生死存亡的戰略高度。
過去幾年,當ChatGPT橫空出世,當微軟將Copilot融入全家桶,當谷歌的Gemini迭代頻繁,整個科技行業以前所未有的速度沖向下一個時代時,那個市值最高、手握最多現金的蘋果,卻像一個沒跟上進度的差生,顯得異常沉默和遲緩。
可以說,面對這場AI差生危機,蘋果的自救之路清晰而務實:用“A計劃”補齊短板,避免被時代淘汰;同時用“B計劃”發揮長處,在自己最擅長的領域,即硬件端側,打一場翻身仗。
編者按:本文轉載自微信公眾號:直面AI(ID:faceaibang),作者:涯角


前瞻經濟學人
專注于中國各行業市場分析、未來發展趨勢等。掃一掃立即關注。
前瞻產業研究院
中國產業咨詢領導者,專業提供產業規劃、產業申報、產業升級轉型、產業園區規劃、可行性報告等領域解決方案,掃一掃關注。


























